
I just earned the Marketing Engineer certification from Profound University with a 90% score. The capstone was a self-improving LinkedIn pipeline I built inside the iDrive Marketing Portal, and the parts the reviewer called out are the same parts I want to walk through here.
The certification feedback
Score: 90% — Passed. Assessed by Tom Stachowiak, Profound University.
| Dimension | Rating |
|---|---|
| Problem identification and prioritization | Excellent (3/3) |
| Decomposition and systems thinking | Meets expectations (2/3) |
| Depth path: agent demo, discovery session, or agent sketch | Excellent (3/3) |
| Presentation and stakeholder communication | Excellent (3/3) |
The feedback that came with my diploma;
Really cool submission overall and definitely one of the more interesting implementations. Awesome job building something that makes socials like LinkedIn actually synergize with content posted across other channels instead of each platform feeling isolated from the others. Keeping that level of consistency in messaging, tone, and content flow across multiple channels is something a lot of teams struggle with, so it was nice seeing that handled well here. The feedback loop and self improving aspect of the system was also very cool. A lot of people stop once the automation works, but having the process continuously adjust itself based on feedback and performance data makes it feel much more practical long term. That was probably the strongest part of the project for me because it showed good thinking beyond just getting the workflow running. Overall there honestly is not much to critique here. The project felt well thought out, the implementation choices made sense, and everything stayed focused on actual usability instead of unnecessary complexity. Very cool project and definitely a strong submission. Congrats!
The two parts the reviewer flagged are the ones I’m proudest of: cross-channel consistency (every module reads from the same brand-context layer, so the voice never drifts between LinkedIn, Reddit, SEO, and the rest) and the self-improving feedback loop (every COO edit becomes training signal for the next draft).
The 2/3 on decomposition is fair. There are seams in the system I’d cut differently if I were building it again — the evergreen filter could be a standalone service rather than a stage inside scan-pipeline.ts, and the voice analyzer’s threshold logic could live in DB triggers rather than a weekly cron checking a counter. Functional but not yet elegant, and definitely worth calling out.
The project that earned the degree
Now the build itself. The capstone is the LinkedIn module of the iDrive Marketing Portal, but it doesn’t sit in isolation, so let me describe the portal first, then zoom into LinkedIn.
An overview of the iDrive portal
I built the iDrive Marketing Portal as a single command center for iDrive Logistics: marketing requests, LinkedIn publishing, Reddit monitoring, SEO tracking, AI visibility, and competitor benchmarking. It contains six modules under one Next.js app, all reading from the same brand-context layer. I loooove Bun btw.
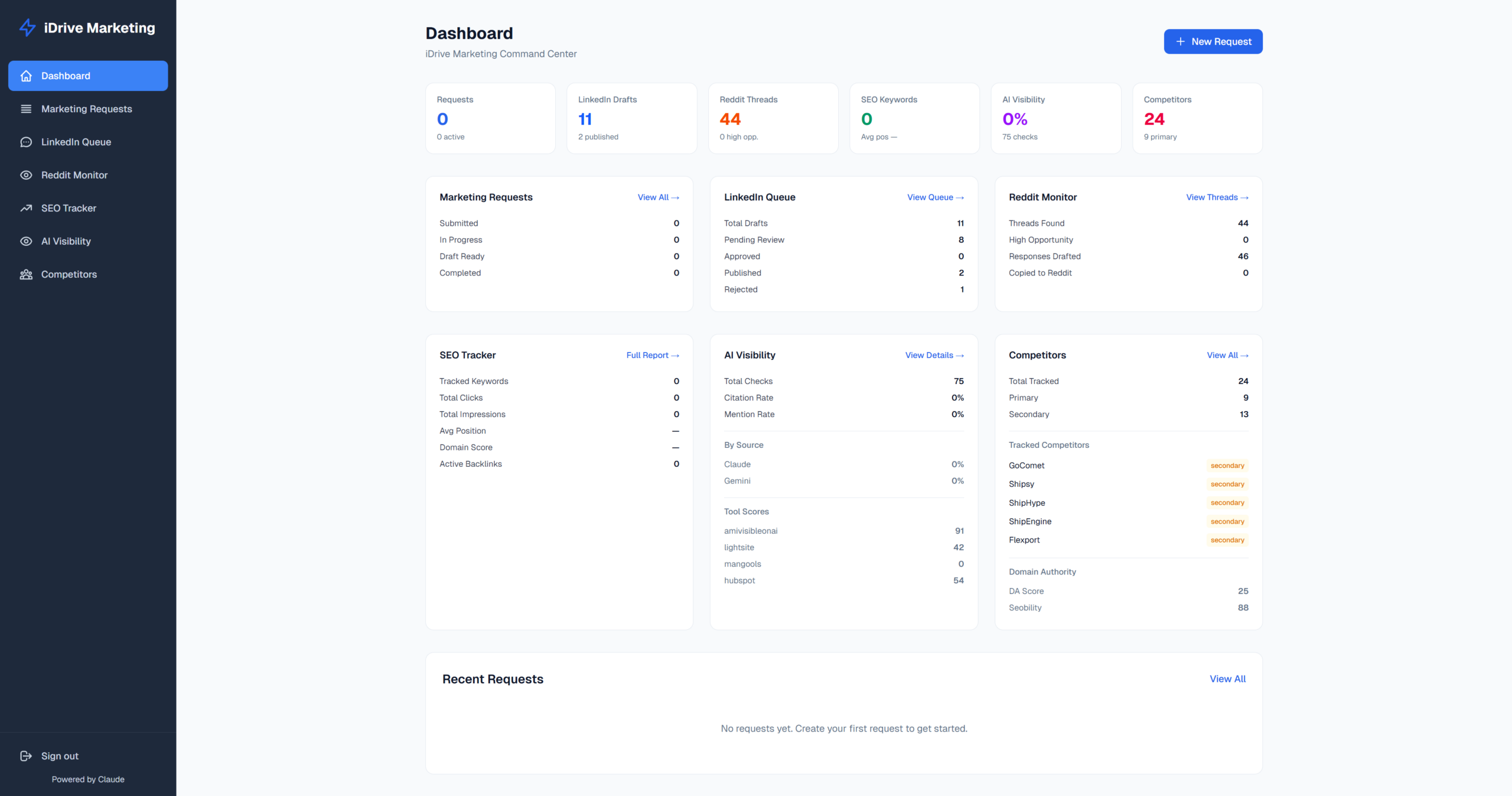
The architectural decision that made everything else easier: every content-generating skill, every API route, every cron pulls from two shared files;
- .agents/product-marketing-context.md (positioning, audience, messaging)
- apps/idrive-marketing-portal/lib/verified-facts.ts (the typed registry of every stat, carrier name, and proof point we’re allowed to cite)
Update a number in one place and it propagates to LinkedIn drafts, Reddit response templates, and the fact-checker simultaneously. That’s the spine the reviewer was complimenting when they said the project made channels “synergize instead of each platform feeling isolated.”
The challenge
iDrive has a library of ~150 blog posts and our COO Brett Haskins whose LinkedIn voice is the brand’s clearest external asset.
The math that didn’t work:
- Drafting an on-voice LinkedIn post from a blog takes 20-40 minutes.
- Brett does not have 20-40 minutes per post, three times a week, for a year.
- The blog library is mostly evergreen, meaning most of those 150 posts could, in principle, fuel LinkedIn for six months. In practice almost none of it gets repurposed.
There was a second, subtler problem: feedback usually evaporates. Every time Brett edits a LinkedIn draft, no one else sees what he changes and why. A generative system that doesn’t capture its corrections will plateau at “pretty good” and never get past it.
I wanted to build something that would help us automate LinkedIn posts from our blog, and knew I had to start with a more narrow scope by refining our voice and tone learnings first. I wanted to get drafts out of Brett’s calendar, and turn Brett’s edits into training signal.
System and workflow architecture
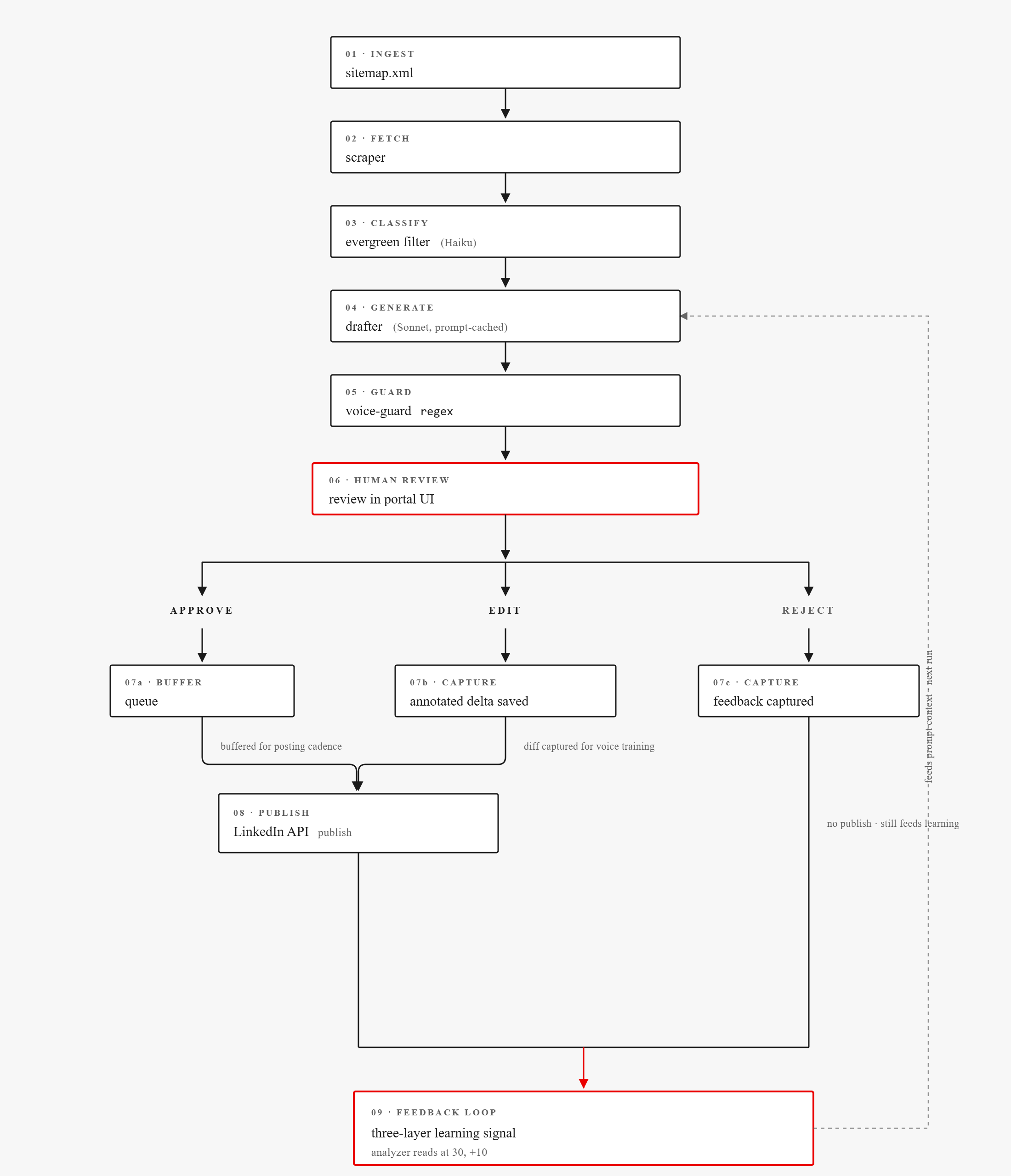
LinkedIn pipeline, end to end:
Stack: Next.js 16.2.4, React 19.2.4, Tailwind v4, Supabase (Postgres + Auth), Claude Sonnet 4.6 for drafting, Claude Haiku 4.5 for the evergreen filter, LinkedIn OAuth + Community Management API for publishing.
How the LinkedIn flow works
Generally, this tool runs on automated scans of our blog, LLM-powered drafts, a UI portal for Brett to approve/reject/send feedback in, and a feedback loop that ensures the tool learns from revisions.
Monday: scan for new blogs
Cron: Vercel cron, Mondays at 08:00 UTC.
Every Monday morning the portal pulls our sitemap (idrivelogistics.com/post-sitemap.xml), diffs against the URLs already in Supabase, and scrapes anything new (typical: 1–5 posts per week).
For each new blog:
- The drafter (Sonnet) produces 2-3 distinct LinkedIn variants, each using a different angle from a six-type enum (data-driven, question-hook, contrarian, tactical-tips, industry-commentary, resource-announcement).
- Voice-guard runs a regex pass against each variant and flags banned phrases (best-in-class, AI-powered, schedule a demo, plus filler like “in today’s world”). Flags don’t block, but they surface inline so Brett can spot AI drift at a glance.
- A Slack notification only fires if the scan produced drafts. This is our reminder that there’s a new draft ready for us.
Tuesday + Thursday: Evergreen sampler from the back-catalog
Cron: GitHub Action, Tue + Thu at 13:00 UTC (09:00 ET).
Mondays cover newly-published blogs. The other two beats of the week reach into iDrive’s ~150-post back-catalog so the LinkedIn cadence isn’t bottlenecked on the publishing calendar.
Selection logic on each Tu/Th run:
- Based on the number of our posts, run a random number generator to pick one out. This is based on our full post sitemap and random integer.
- Exclude posts published in the last 7 days — those belong to Monday’s scan, so no need to double-cover.
- Dedup: skip if a draft already exists in Supabase for that URL, or if it’s already moved through the system in any state (approved, published, rejected). With ~150 posts to choose from, the duplicate-hit rate is low and the loop just retries.
- Evergreen filter (Haiku) reads the post and decides if it’s still useful 12+ months out. Holiday-specific or Q-number-specific posts get filtered.
- The model also extracts an angle_summary (the post-worthy LinkedIn hook) and 2–5 topic_tags from a fixed taxonomy (carrier-strategy, peak-season, tariffs, returns, 3pl, dtc, etc.)
- If evergreen, the drafter (Sonnet) produces 2–3 distinct LinkedIn variants — each using a different angle from a six-type enum (data-driven, question-hook, contrarian, tactical-tips, industry-commentary, resource-announcement). Same drafter and voice-guard regex pass as Monday.
- Slack notification inline, so Brett can react in-channel without opening the portal.
- If steps 2-4 reject the pick: retry up to N attempts, then stay silent. Better than “nothing to suggest” noise.
Why RNG-then-evaluate, not pre-draft-the-whole-library? With 150 evergreen-eligible posts, pre-drafting them all up front would burn Sonnet budget on content that might never reach Brett’s queue. Picking one at random and only paying for the evergreen and draft calls on the survivor keeps per-run cost predictable (one Haiku call + at most one Sonnet draft per Tu/Th) and means the system always reflects the latest state of the back-catalog, including posts iDrive added since the last full scan.
Why a GitHub Action, not another Vercel cron? Vercel Hobby caps the project at four cron jobs and I’d already spent them on the portal. The workflow just curls the portal endpoint with a shared CRON_SECRET — all the actual logic (sitemap fetch, RNG, dedup, evergreen filter, drafter, Slack post) still lives in the portal. Same pattern as the competitor scanner. A small detail that tells you whether the system was designed or just assembled.

The Settings page’s “Recent scan runs” log confirms the loop is firing. Weekly-cron entries on 5/11/2026 and 5/4/2026, plus several slack-suggest runs in late April. Tu/Th quietly stays silent on weeks where the RNG keeps landing on already-covered posts, which is the intended behavior.
Voice and tone documentation
The drafter’s system prompt is the longest single file in the LinkedIn module (~12 KB), and it does five things:
- Five core voice attributes — confident, pragmatic, partnership-first, solutions-oriented, slightly irreverent when honest.
- Four structural templates — Educational/Data-driven, Carrier deep-dive, Resource/Announcement, Industry commentary. Every draft has to match one.
- Banned-phrase list with rewrites — “best-in-class” → cite a metric. “AI-powered” → “intelligent rate shopping.” “Guaranteed savings” → “21% average client savings.” Filler (“in today’s world,” “at the end of the day”) gets cut.
- Approved vocabulary — “carrier diversification” (not “switching”), “True Landed Cost” (not “total shipping cost”), “47-point invoice audit” (not “audit”).
- Four verbatim Brett posts as few-shot examples — Q1 surcharges, tariffs commentary, parcel pricing contrarian, peak season carrier capacity. These are the anchor. Everything else in the prompt is rules; these are the texture.
The prompt is cached as the first prompt-cache block in every drafter call. Cache hit rate on iDrive’s volume sits around 90%, which keeps cost per draft below 2¢.
None of the 11 currently-generated drafts triggered a voice-guard flag — meaning Sonnet plus the cached voice prompt has been clean enough to avoid the regex tripwires so far. If a flag fires, it surfaces as an orange chip with the banned phrase + a 60-character context snippet inline on the card.
A user-friendly UI
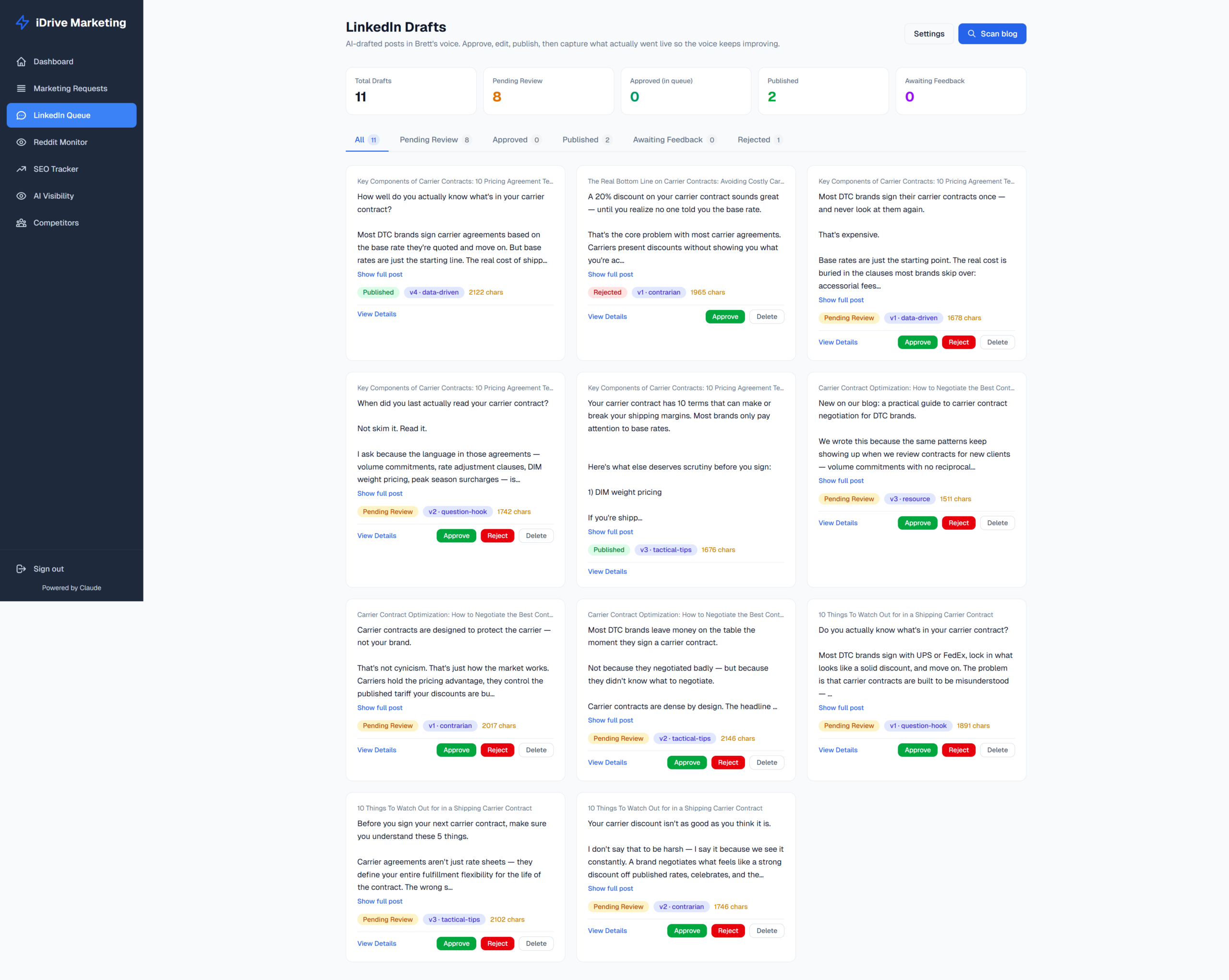
We have six tabs across the top: All / Pending Review / Approved / Published / Awaiting Feedback / Rejected, each with a live count. The grid renders draft cards three-wide on a desktop.
Each card shows:
- The proposed body and hashtags
- Source blog title and angle tag
- Any voice flags (orange chips with the banned phrase + a 60-char context snippet)
- Approve / Reject / Edit / Regenerate-with-steer / Publish-now buttons
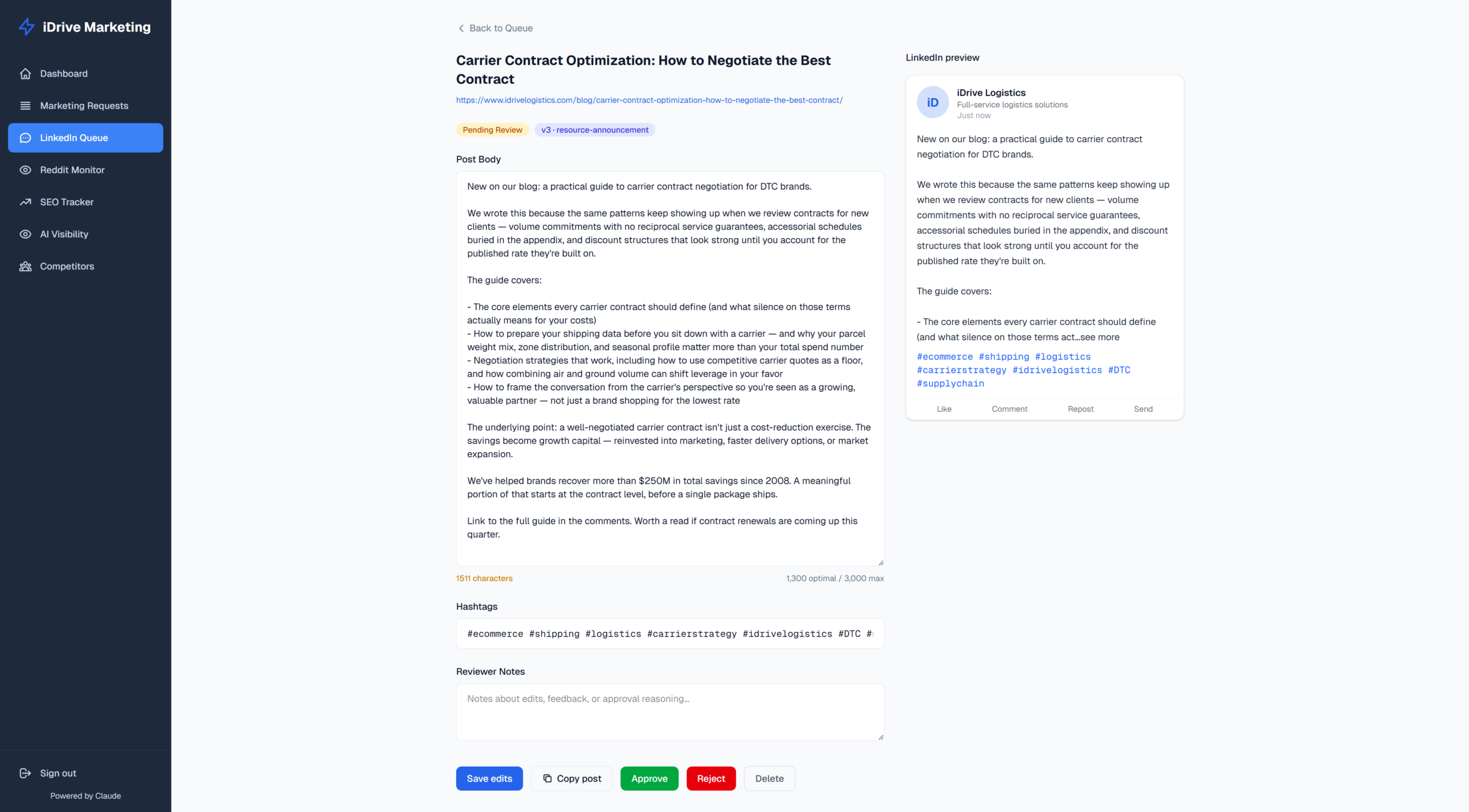
The “Awaiting Feedback” tab surfaces posts that have been published but where we haven’t yet captured what Brett actually pasted into LinkedIn after final tweaks. That’s important because it captures the corrections that slipped past portal review.
The feedback and learning loop
I love this part, it’s really the centerpiece that will turn the tool into a huge time-saver.
There are three layers to this feedback loop;
- The original AI draft from Sonnet
- Portal-edited version that Brett approved in our UI
- LinkedIn-final version that actually got pasted into LinkedIn (sometimes it was edited again)
- The voice analyzer sits on top of those three layers.
Trigger: A weekly Vercel cron checks if analysis is due. The first analysis fires at 30 approved+published posts, then every +10 after that. Running the check weekly means there’s at most a seven-day gap between hitting a threshold and the addendum being refreshed.
What it does: When due, Sonnet 4.6 reads up to 80 approved/published drafts (showing all three layers side-by-side), up to 20 rejected drafts as negative signal, and angle + topic tallies for what’s resonating. It returns a markdown addendum under 400 words plus 3–7 key signals — only patterns visible in ≥3 examples, never extrapolation from one-offs.
The compounding bit: The addendum is stored and cached. On the next drafter call, the system prompt assembles as two cache blocks. The baseline cache block almost never changes (cache hit). The addendum block invalidates only when a new addendum is generated. Iteration N’s addendum is generated against drafts that were themselves informed by iteration N-1’s addendum, so the learning compounds — but the original voice bible at system.brett-voice.md is never overwritten. The addendum extends; it doesn’t replace.
Why this works as feedback. Most “AI improves over time” systems require explicit ratings — thumbs up, thumbs down, a 1–5 score — which Brett would never give consistently because nobody does. This system requires no extra action from Brett. Approving is feedback. Editing is feedback. Rejecting is feedback. The further the portal-edited version drifts from the AI’s original, the louder the signal. This system leverages editorial work into training data instead of forgetting it like what happened when I was running it manually.
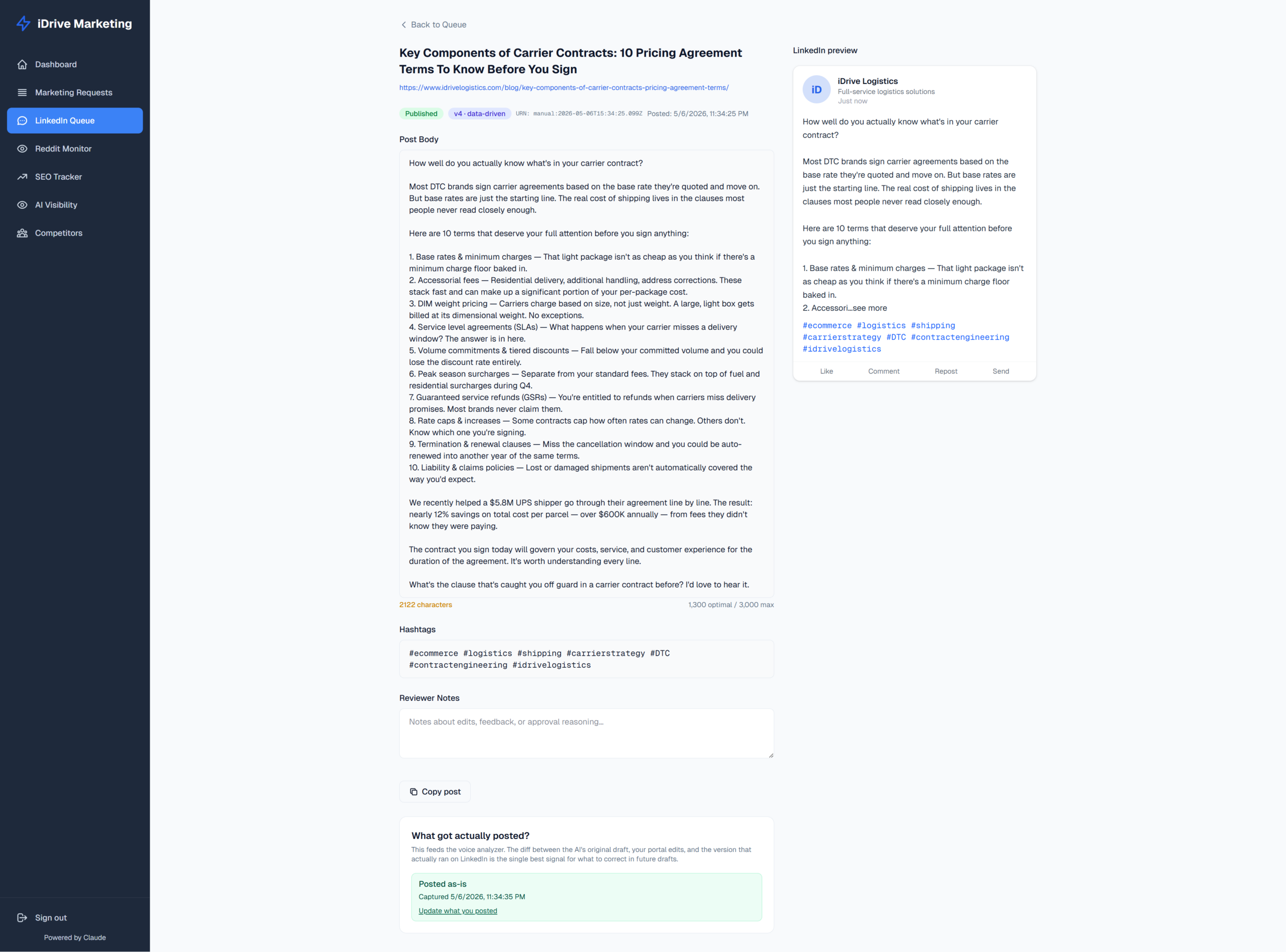
Roadmap: From reviews/approvals to publish
Today, the process still relies on Brett’s approval and my publish to work. Once the voice and tone have improved to the point where Brett is just clicking “Approve” on everything (aiming for 29/30), I’ll set the system up to auto-publish to LinkedIn without waiting for our permission and feedback. Hopefully by then my LinkedIn Developer app’s Community Management API has finally been approved!
Gates;
- Voice analyzer has run more than 3 cycles, with 60 approved and published posts processed
- The average word-level differences between draft and publish drops below 5
- Brett has approved 28/29 out of the most recent 30 posts with fewer than 5 word changes (fun fact about that number, I chose 95% for no special reason other than we’ve been learning about the 1.96 t-stat halo in my Oxford EMBA Analytics course).
By the next phase, drafts will auto-publish on a set cadence, and the voice analyzer will continue to learn from any post-publish edits we make directly on LinkedIn. That feedback loop should continue down the line.
Results
System (built and shipped)
| Metric | Value |
|---|---|
| Modules unified under one brand-context layer | 6 (Requests, LinkedIn, Reddit, SEO, AI Visibility, Competitors) |
| Blog library scanned | iDrive Logistics blog sitemap (idrivelogistics.com/post-sitemap.xml) |
| LLM models in production | Claude Sonnet (drafting + voice analysis), Claude Haiku (evergreen filter) |
| Scheduled jobs | 3 (Vercel cron Mon, Vercel cron weekly voice check, GH Action Tue/Thu) |
| Prompt cache strategy | Two-block: immutable voice guide + auto-updated addendum |
| Approved posts before first voice analysis | 30 |
| Approved posts between subsequent analyses | 10 |
| Feedback layers captured per post | 3 (AI original → portal edit → LinkedIn-final edit) |
| Banned phrases enforced via regex | 16 |
| Voice templates the drafter must match | 4 (A: Educational · B: Carrier deep-dive · C: Resource · D: Industry commentary) |
| Angles the drafter rotates through | 6 |
| Audience registers supported | 4 (enterprise, 3pl, dtc, f&b) |
Pipeline (live data, captured 12 May 2026)
| Metric | Value |
|---|---|
| Drafts generated to date | 11 |
| Posts published | 2 |
| Drafts in pending review | 8 |
| Drafts rejected | 1 |
| Voice flags raised by guardrail | 0 (Sonnet + cached voice prompt has been clean) |
| Confirmed weekly-cron runs (May) | 2 (5/4 + 5/11) |
| Slack-suggestion runs (late April) | 4 (mix of “no new blogs” + 1 graded) |
| First voice analysis | Pending — 28 more approvals needed to hit the 30-post threshold |
I was able to get this live and launched because I could identify exactly what I wanted done, and then work backwards to achieve it. When I set out to build a big giant fuzzy solution, I burned through tokens and would stop at 3 a.m. without really understanding what I had done.
If you want some help figuring out how AI fits into your workflows, I’d love to poke around your company and ask too many questions! Let’s chat.
Built and shipped by Rachel Go, CMO of iDrive Logistics. Submitted for Profound University’s Marketing Engineering certification, May 2026.
Stack: Next.js 16 (App Router), React 19, Tailwind v4, TypeScript, Supabase (PostgreSQL), Claude Sonnet 4.6, Claude Haiku 4.5, LinkedIn OAuth + Community Management API, Slack incoming webhooks, Vercel Cron + GitHub Actions for scheduling, Bun workspaces monorepo.